转载请附原文链接:Volley学习笔记之简单使用及部分源码详解
一、使用背景简介
现在大多数手机 App 几乎都离不开网络技术,需要手机端与网络服务端进行数据交互,Android 系统中主要提供了两种方式来进行HTTP通信,HttpURLConnection 和 HttpClient,在初学 Android 的时候,这两个类是我们最开始学着使用的,但是在使用过程中需要调取各种API,进行封,然后请求到的结果需要自己去解析,最后再将解析到的数据进行封装存到数据库,整个过程,相当复杂,而且重复性很高,于是针对这种情况,网络上就有大神封装了各种第三方框架供我们使用,将这些复杂冗余操作进行组合优化,使得整个编写过程得以简化,只需简单配置几行代码就可以完成整个流程操作。今天我们介绍的 Volley 就是其中一个优秀第三方框架。笔者所在公司目前项目使用的就是Volley ,所以在使用的同时决定写一系列笔记分析,从学会简单使用,到最后的 Volley 源码分析一系列循序渐进的流程来理解Volley的实现原理。
二、Volley简介
Volley 是 Google在 Google I/O 2013 大会上 推出的 Android 异步网络请求和图片加载框架。
主要作用 :实现异步网络请求、图片加载。
主要特点:
(1). Volley基于接口设计,扩展性强,我们可以根据我们的需求定制自己想要的请求方式方法。
(2). 一定程度符合 Http 规范,包括返回 ResponseCode(2xx、3xx、4xx、5xx)的处理,请求头的处理,缓存机制的支持等。并支持重试及优先级定义。
(3). 默认 Android2.3 及以上基于 HttpURLConnection,2.3 以下基于 HttpClient 实现。(4). 支持指定请求的优先级。
(5). 高并发网络连接。
使用下载地址:https://android.googlesource.com/platform/frameworks/volley
可以使用git 下载命令 git clone https://android.googlesource.com/platform/frameworks/volley
- 编译jar:
android update project -p . ant jar
- 编译jar:
添加volley.jar到你的项目中
不过已经有人将volley的代码放到github上了:
https://github.com/mcxiaoke/android-volley,你可以使用更加简单的方式来使用volley
三、简单使用
使用Volley框架实现网络数据请求主要有以下三个步骤:
- 创建RequestQueue对象,定义网络请求队列,RequestQueue内部的设计就是非常合适高并发的,因此我们不必为每一次HTTP请求都创建一个RequestQueue对象,避免非常浪费资源的,一般全局使用一个就可以。
- 创建XXXRequest对象(XXXRequest对象可以自己继承Request类进行封装定义,也可以使用Volley已经为我们提供的的StringReqeust、JsonArrayRequest、JsonObjectRequest),这个类主要是功能是传入请求网址、解析返回数据、回调监听返回数据等功能的实现,也是我们经常继承包装的类,在这里可以实现我们想要的返回数据类型。
- 把XXXRequest对象添加到RequestQueue中,开始执行网络请求。
怎么样,这样看来整个网络请求是否是变得便捷,不需要你去考虑,如何调取Http请求各种API,不需要考虑异步等问题,Volley已经帮助我们完成,下面简单以StringReqeust为例子发起一个Get请求,编写一个小的Demo用例,结合代码,加深理解:
网络请求队列一般都是整个APP内使用的全局性对象,因此最好写入Application类中,全局只使用一个,避免浪费资源:
|
|
我们还需要修改AndroidManifest.xml文件,使APP的Application对象为我们刚定义的MyApplication,并添加INTERNET权限:
|
|
创建StringReqeust对象,并将其添加到RequestQueue中:
|
|
好了,这样我们就完成完成了StringRequest请求操作,在onResponse方法内得到我们想要的请求结果String 类型数据。
四、使用思考
在上面使用StringRequest请求过程中,我们只需要简单三步就完成了整个请求,那么有没有想过,Volley内部是如何实现的呢,思考以下几个问题:
- 如何实现高并发请求
- 如何实现异步请求
- 如何实现数据缓存
- 内部是如何各种继承,组合封装最后几行代码就可以实现请求功能,但是使用拓展性又那么强。
相信不想只做代码搬运工的你在使用过程中也会有这些甚至更多疑问,笔者在使用过程中一直好奇这些,否则在项目中只是简单调用人家已经封装好的几行代码,总感觉自己是一个搬运工,不知其所以然,所以现在决定,静下心来,去尝试分析一下Volley源码,以此记录分享。
五、源码分析
首先我们来看看Volley官方给出的一张Volley工作流程图

下面将这张图翻译如下:
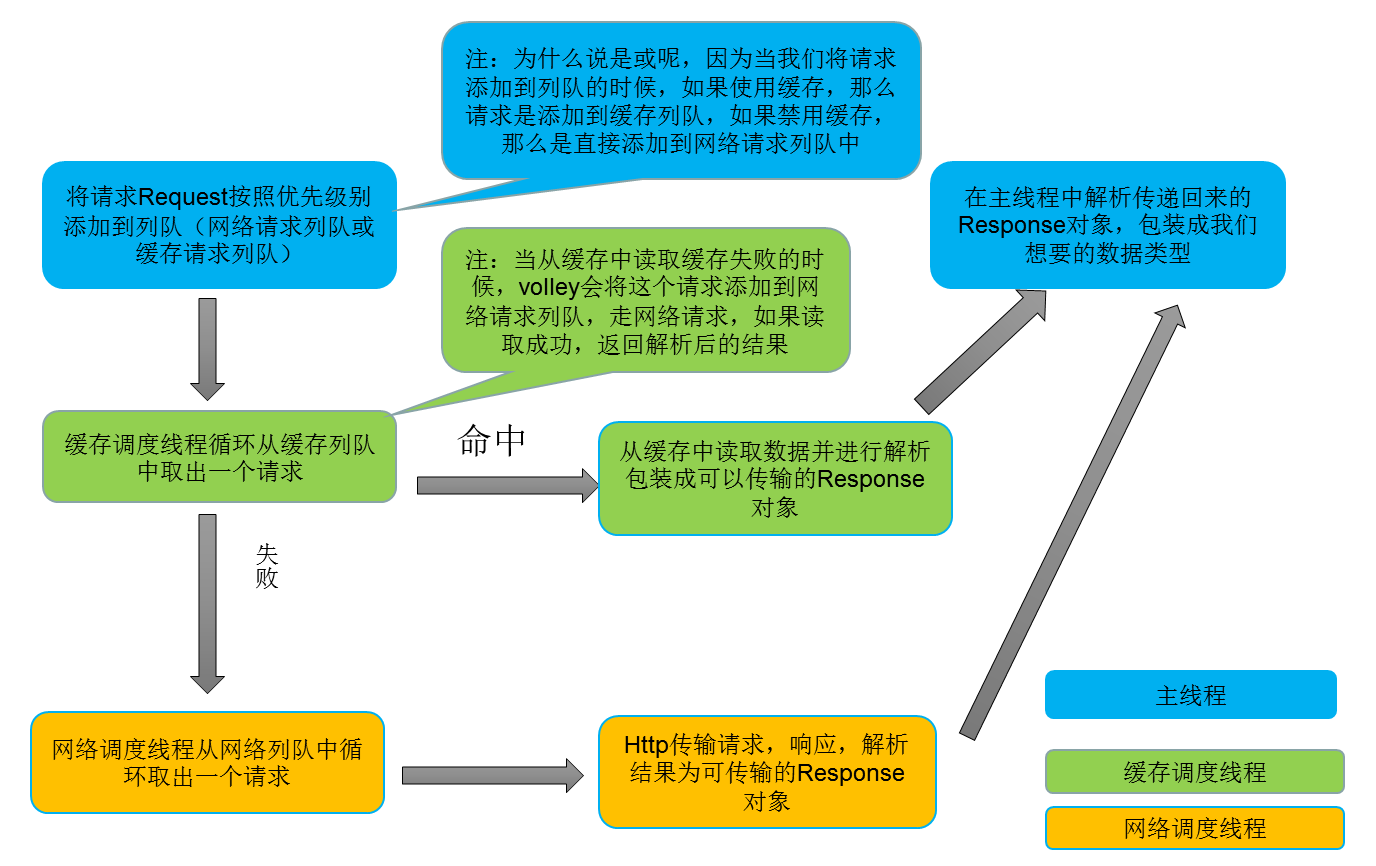
通过上面这张图我们可以对Volley工作流程有一个大概的印象,下面我们根据这张流程图以及Volley使用过程来结源码进行分析:
首先从我们使用的入口Volley.newRequestQueue(context)方法来来作为我们分析的切入点,代码如下:
|
|
这个方法仅仅只有一行代码,只是调用了newRequestQueue()的方法重载,并给第二个参数传入null。那我们接着分析带有两个参数的newRequestQueue()方法中的代码,如下所示:
|
|
这个方法也很简单,直接调用了含三个参数的构造方法,那么我们接着看看含三个参数的构造方法代码:
|
|
这个方法代码稍微多一点,代码已经注释,这个构造方法主要是new 了一个 负责处理网络请求部分的stack对象,然后 用BasicNetwork将stack进行包装处理,又new了一个负责缓存部分的DiskBasedCache对象,并将这两个参数传入了列队queue中,并启动了列队;这里说明一下,在创建HttpStack对象的时候是比较了一下版本号,如果Build.VERSION.SDK_INT >= 9( API大于9), stack = new HurlStack();这里是因为在Android 2.2版本之前,HttpURLConnection一直存在着一些令人厌烦的bug,在Android 2.3版本及以后,HttpURLConnection则是最佳的选择。它的API简单,体积较小,因而非常适用于Android项目。压缩和缓存机制可以有效地减少网络访问的流量。到这里我们就完成使用volley的第一步分析,即获取RequestQueue对象,那么接下来我们分析下RequestQueue构造方法的实现:
|
|
下面分析含三个参数的构造方法代码:
|
|
含四个参数的构造方法代码如下:
|
|
到这里我们来我们发现从调用含有两个参数的RequestQueue构造方法是逐渐调用三个、四个参数构造方法,那么最终实现了:mCachesd卡缓存类的实例化,network网络请求包装类 的实例化,创建了一个数量为4的NetworkDispatcher数组,mDelivery=new ExecutorDelivery(new Handler(Looper.getMainLooper())网络请求结果回调类的实例化。那么这里我们看一下回调网络请求结果类ExecutorDelivery构造方法代码:
|
|
这里的handler为new Handler(Looper.getMainLooper()),即handler是创建在主线程中,所以当调用 handler.post(command)的时候,是将网络请求结果发送到主线程主去处理,这样就完成了异步任务,将子线程中网络请求的结果发送到主线程中去处理。以上就完成了构造RequestQueue对象过程中的代码分析。
下面还有一个疑问要分析就是我们在调用volley的时候执行的RequestQueue.add()方法,分析一下是如何将请求添加到缓存列队和网络请求列队,以及如何进行管理。
|
|
下面我们来捋一捋request是如何被添加到请求列队中的步骤如下:
1、当add一个请求request时候,首先该请求会被添加当当前请求列队mCurrentRequests中。
2、如果该请求不使用缓存那么直接被添加到网络请求列队mNetworkQueue结束方法。
3、如果该请求使用了缓存,那么先判断mWaitingRequests列队中是否有该请求,如果有那么添加到mWaitingRequests中,如果没有直接添加到缓存请求列队mCacheQueue中。
到这里我们理解了一个请求是如何被添加到列队中,但是同时会产生一个疑问就是mCurrentRequests和mWaitingRequests这两个列队的作用是什么,以及如何调用的,我们初略猜想一下,这两个列队中维护的请求应该在一个请求结束的时候,将该请求移除,那么应该是RequestQueue的finish方法中进行调用,那么下面我们来看一下代码:
|
|
上面代码只需要看注释部分即可,并不复杂,那么RequestQueue的finish应该是什么时候调用呢,我们猜想应该是在一个request方法请求结束的时候,我们来看一下在Request类的finish方法中代码是否如此:
|
|
上面代码我们在第三行看到了mRequestQueue.finish(this);那么request方法结束请求有三种可能分别是:手动调用request.cancel方法取消请求、request请求成功回调成功结果、request请求失败回调失败结果,这三种请求都是表面当前request请求结束,那么我们分别看一下这三处的代码是否进行了调用,我们以网络请求线程NetworkDispatcher为例(缓存线程调度原理相同):
|
|
然后看一下请求结果回调类ExecutorDelivery的run,执行了该方法表明将request请求结果进行了回调,所以request.finish()方法在此处也有调用:
|
|
这样mCurrentRequests和mWaitingRequests这两个列队的管理基本就捋清楚了。
下面我们就要思考获取到requestQueue对象,调用requestQueue.add(request)方法后,是如何启动网络请求的,那么我们看到在RequestQueue构造方法中有一行代码 queue.start()方法,那么接下来我们来分析一下这个方法具体内容:
|
|
上面代码主要实现功能是创建一个缓存事件调度线程并启动,然后循环创建了n个网络请求线程调度networkDispatcher对象,这里n= mDispatchers.length。mDispatchers数组的长度即是构造RequestQueue过程中传入的参数DEFAULT_NETWORK_THREAD_POOL_SIZE 即数量为4,也就是说创建了4个负责网络请求调度的线程。下面我们一起分析一下CacheDispatcher缓存调度线程代码,CacheDispatcher 继承自Thread,是一个线程,先看一下构造方法:
|
|
然后主要看一下run方法:
|
|
这个run方法主要作用是:启动后会不断从缓存请求队列中取请求处理,队列为空则等待,请求处理结束则将结果传递给ResponseDelivery 去执行,将请求结果发送到主线程中。当结果未缓存过、缓存失效或缓存需要刷新的情况下,该请求都需要重新进入NetworkDispatcher去调度处理。这里有一行代码mDelivery.postResponse(request, response);是将请求结果发送到主线程中,前面我们提到是利用handler.post()方法执行,那么我们看看ExecutorDelivery 类的postResponse的具体细节:
|
|
就一行代码,调用含三个参数的构造方法,那么我们继续追溯:
|
|
这里的mResponsePoster就是在构造ExecutorDelivery 时候生成的Executor对象,代码如下:
|
|
而ResponseDeliveryRunnable继承Runnable,所以当调用mResponsePoster.execut(new ResponseDeliveryRunnable(request, response, runnable))方法时候就会将ResponseDeliveryRunnable对象发送到主线程中,那么我们看一下ResponseDeliveryRunnable类的run方法:
|
|
这段代码我们看自定义Request时候需要复写的方法 mRequest.deliverResponse(mResponse.result);和mRequest.deliverError(mResponse.error)。到这里请求回调的疑问我们已经解决。
下面我们先分析一下NetworkDispatcher网络缓存线程,NetworkDispatcher 继承自Thread,也就是说NetworkDispatcher 是一个线程先看一下构造方法:
|
|
然后看一下复写的run方法:
|
|
run方法启动后会不断从网络请求队列中取请求处理,队列为空则等待,拿到请求后,则执行网络请求,请求处理结束则将结果传递给 ResponseDelivery 去执行后续处理,并判断结果是否要进行缓存。
下面我们来捋一捋volley如如何进行网络请求、缓存请求和请求结果的回调,步骤如下:
1、创建了一个缓存事件调度线程CacheDispatcher,负责从缓存列队中读取请求,然后从缓存中读取数据,进行解析返回,从缓存中读取数据为null,或者数据过期、需要刷新,那么将请求添加到网络请求列队。
2、创建了四个网络请求事件调度线程NetworkDispatcher,负责处理网络请求,并解析请求结果进行返回,并将结果缓存到本地。
3、创建了一个请求结果回调类ResponseDelivery,负责将请求结果返回到主线程,原理是利用handler将结果post到主线程。
到这里volley框架的主要流程我们基本梳理通顺了,下面我们在看一下细节方面,网络请求是如何执行的,上面代码中执行网络请求代码mNetwork.performRequest(request),其中mNetwork就是我们在构造RequestQueue时候传入的BasicNetwork对象,那么看一下具体代码如下:
|
|
这段方法中大多都是一些网络请求细节方面的东西,部分已经添加注释,我们抓重点看即可,其中httpResponse = mHttpStack.performRequest(request, headers);这一行代码中的mHttpStack就是我们在构造RequestQueue的时候传入的HttpStack对象,负责处理http网络请求的,然后就是有几处代码是return new NetworkResponse(HttpStatus.SC_NOT_MODIFIED, null, responseHeaders, true, SystemClock.elapsedRealtime() - requestStart)),其中区别就是参数不同,所以这个方法其实只要实现功能就是调用HttpStack处理网络请求,并将结果进行包装转换为可被ResponseDelivery处理的NetworkResponse对象返回。
下面我们看一下mHttpStack.performRequest(request, headers)这个方法是如何处理网络请求的(以HurlStack类为例):
|
|
这段代码中我们终于看见了我们熟悉的HttpURLConnection对象,并进行了一系列的参数设置,解析返回数据返回HttpResponse对象。到这里负责执行网络请求部分的内容我们也梳理结束。
至此,关于volley的学习笔记到此结束,如有理解错误地方,还请指教!!
最后其实网络上关 Volley源码分析有很多文章,东西都差不多,但是每个人的侧重点和分析角度以及能否把事情讲的通俗易懂差别就大了,关键是要找到适合自己的,如果感觉本人分析你读着比较懵逼,那可能是我写的不清真,那么可以出门左拐黑丫山上的小帅比 对Volley的深入分析 和郭霖大神的博客去看一下,如果还是看不懂,那就有肯能是你理解的不清真了(just a joke) !!